Unicode 编码的基础知识
Unicode 之前
- 大陆使用的是 GB2312(扩展的还有 GBK、GB18030)
- 台湾:Big5
- 美国:ASCII(ISO-8859-1)
- 拉丁语系:ISO/IEC 8859-1 ~ ISO/IEC 8859-15(中间废弃了 12)
上述这些标准在本地区使用当然没问题,但是如果要跨地区交流就会出现问题。因为同样的码值体系中对应的字是不同的。如果要在同一篇文档里显示不同的编码的文字,那是一个不可能的任务。
Unicode
Unicode 的发明就是为了解决上面的问题:
-
鼎鼎大名的国际标准化组织 ISO 推出了 ISO/IEC 10646 标准,该标准定义了一个统一的字符集:Universal Multiple-Octet Coded Character Set,简称 UCS。它涵盖两种编码方式:UCS-2 和 UCS-4,它们分别使用 16bit 和 32bit 存储一个字符,UCS-4 等价于 UTF-32,但是 UCS-2 和 UTF-16 存在一定差别,UCS-2 只是 UTF-16 的子集。
-
美国一个软件制造商协会推出一套统一字符集:Unicode,最开始它是设计为一个字符存储于2个字节的编码方式,也就是UTF-16。(现在的UTF-16不再仅仅只支持2个字节了)
两家机构合并了彼此的研究成果,诞生了现在的 Unicode。
enabling people around the world to use computers in any language。
Unicode 由两个部分组成:
- UCS(Universal Character Set):把不同的语言中的字符都放进去,为每个字符分配唯一的 码值(术语 Code Point);
- UTF(Universal Transformation Format):定义了存储和传输方式;
我们谈论的 Unicode 编码,严格来讲是指 UCS,也可以叫做「字符集」。比如中文字符「正」的码值十进制是 27491,十六进制表示是 6B63。讨论 Unicode 时,常用的表示法是 U+6B63。
UCS 只是概念,在实际使用中还需要编码成为二进制才能读取、存储、传输,所以才需要有 UTF。
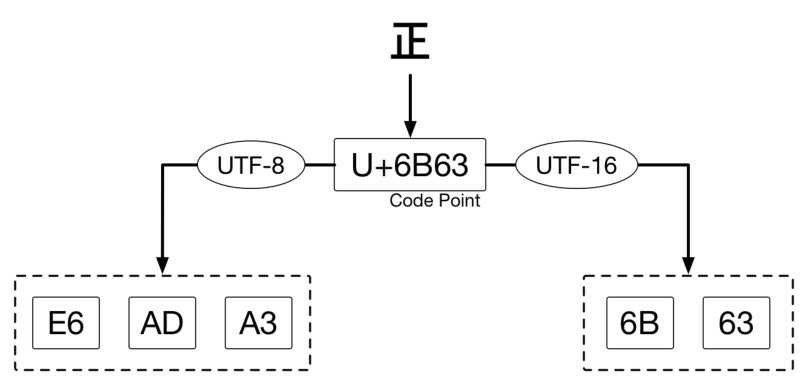
- 如果使用 UTF-8 编码「正」,需要使用 3 字节:
E6 AD A3 - 如果使用 UTF-16 编码「正」,需要使用 2 字节:
6B 63
为了能在全世界通行,UCS 空间设计得很大,码值从 0 到 1 114 111。2017 年 6 月发布的 Unicode 10.0 标准中。280 016(25%)已经分配完毕,其中 136 755(12%)分配给了字符,137 468(12.3%)分配给了私有用途,2048分配给了代用码(surrogates),66 分配给了非字符用途,剩下834 096(75%)尚未分配。
整个 UCS 又可以分为 17 个「平面」(Planes),每个平面包含 65 536 个码值(二者的乘积正好是1 114 112)。这 17 个平面的编号从 0 到 16,其中编号为 0 的平面称为「基本多语言平面」(Basic Multilingual Plane, BMP),对应的码值从 0 到 65 535,日常用到的绝大多数文字字符都包含在这个平面里。除了 BMP 之外,其他平面称为「补充平面」(Supplementary Plane)。
因为假设所有的字符都可以用 2 字节进行表示,所以早期出现的一种 Unicode 编码格式是 UCS-2,它用 2 字节表示所有字符。要注意的是,它的名字里虽然有 UCS,其实和 UTF-8 一样,是一种 传输编码。
最开始,UCS-2 确实工作得不错,但随着技术的发展,大家很快发现 BMP 不够用了,需要启用新的平面,而 UCS-2 因为先天限制,不可能有空间表示更多的字符了。
于是, UTF-16诞生了。
UTF-16 的设计思想非常巧妙。如果要表示的字符在 BMP 内,直接照搬 UCS-2 就可以。如果不在 BMP 内,也就是码值超过了 65 536,则利用 BMP 中预留的 U+D800 到 U+DFFF 这 2048 个代用码(本身是没有意义的)来解决。
这 2048 个代用码分为两段,U+D800 到 U+DBFF 和 U+DC00 到 U+DFFF。对任何一个码值,只要其第一个字节在 D8 到 DF 之间,它一定不是 BMP 中原有的字符,所以可以放心用来当替代品表示其他字符。
对于 BMP 之外的字符,UTF-16 定义的转换规则如下:
- 将码值减去 0x010000,得到一个20位的数值。
- 将这个数值的高 10 位加上 0xD800,得到的码值作为高位代用码(High Surrogate)。
- 将这个数值的低 10 位加上 0xDC00,得到的码值作为低位代用码(Low Surrogate)。
- 将高低两段代用码组合起来,得到 4 字节序列,就是该字符的 UTF-16 编码值。

也就是说,UCS-2 是 UTF-16 的子集,在 UTF-16 编码格式下,用于表示一个字符的字节数可能是变化的,或者是 2 个字符,或者是 4 个字符。
UTF-16 确实解决了空间不够的问题,但它也有问题:本来在 ASCII 编码中,英文字符只占用1字节,使用 UTF-16 之后则必须占用 2 字节,所消耗的空间瞬间增长了一倍。在存储空间还很宝贵的时代,这无疑是不小的负担。所以,UTF-8 编码才能够大行其道。
UTF-8
与 UTF-16 类似,UTF-8 编码也是一种变长传输编码。与UTF-16 不同的是,它的编码单位不是 2 字节,而是 1 字节,也就是说,UTF-8 编码的字符,最少只用 1 字节。这样不但兼容原本就是单字节的 ASCII 编码,存储英文资料时也节省了大量的空间。
转换规则:
- 单字节的字符,字节的第一位设为 0,后面 7 位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII码是相同的。
- 对于 n 字节(n = 2,3,4)的字符,第一个字节的前 n 位都设为 1,第 n+1 位设为 0,后面字节的前两位一律设为 10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
| 字节数 | 最小值 | 最大值 | UTF-8 编码值 |
|---|---|---|---|
| 1 | U+0000 0000 |
U+0000 007F |
0xxxxxxx |
| 2 | U+0000 0080 |
U+0000 07FF |
110xxxxx 10xxxxxx |
| 3 | U+0000 0800 |
U+0000 FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
| 4 | U+0001 0000 |
U+001F FFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
举例:

比如,希伯来语字母 aleph(א)的 Unicode 代码是 U+05D0,我们按照上面的表格将其转化成 UTF-8,U+05D0 属于 U+0080 到 U+07FF 区域,根据以上表格,说明它使用双字节的格式:110xxxxx 10xxxxxx.
十六进制的 0x05D0 换算成二进制就是 101-1101-0000。这11位数按顺序放入 x 部分:11010111 10010000。
因为大部分中文字符都落在 0800 到 FFFF 这个区间,所以在 UTF-8 编码格式下,一个中文字符要占用 3 字节。而在 UTF-16 编码格式下,一个中文字符只占用 2 字节。
UTF-8 凭借在传输英文资料时节省大量空间、直接与 ASCII 兼容等优势,赢得了越来越多的开发者。如今,除了少数系统内部使用 UTF-16,大部分场合,UTF-8都已经成了默认传输标准。
如果我们需要在代码中处理 Unicode 字符,一定是指定它原始的码值,而不是传输编码。
BOM
编码方式使用的最小字节组合称为码元(Code Unit),UTF-8 的码元是 1 个字节,UTF-16 的码元是 2 个字节,而 UTF-32 的码元是 4 个字节。码元大于一个字节则在存储和传输时就要考虑字节序的问题,字节序分两种,一种是大端方式(Big Endian),一种是小端方式(Little Endian)。
Unicode 规范中规定 UTF-16 和 UTF-32 需要使用BOM(byte order mark)描述字节序。BOM是一段添加在数据流开头的字符串。UTF-8 的码元是以一个字节为单位,所以可以不加 BOM 前缀,而且 Unicode 规范也推荐不要在 UTF-8 编码的内容添加 BOM 前缀。
参考资料
 微信支付
微信支付 支付宝
支付宝 狗狗币
狗狗币